FastTrackML
Experiment tracking server focused on speed and scalability
Highlights
Blazing Fast
FastTrackML is a rewrite of the MLFlow tracking server with a focus on performance and scalability.
Modern Aim UI
Use the modern Aim UI alternative for a seamless experience.
Drop-in Replacement
Use the Classic UI to get the same experience as MLFlow’s tracking server. But even faster.
Quickstart
Run FastTrackML
Using pip
Note: This step requires Python 3 to be installed.
Install FastTrackML:
pip install fasttrackml
Run the server:
fml server
Using a script
Install on Linux and macOS:
curl -fsSL https://fasttrackml.io/install.sh | sh
Install on Windows:
iwr -useb https://fasttrackml.io/install.ps1 | iex
Run the server:
fml server
Using Docker
Note: This step requires Docker to be running.
Run the server within a container:
docker run --rm -p 5000:5000 -ti gresearch/fasttrackml
Verify that you can see the UI by navigating to http://localhost:5000/.
Track your first experiment
Note: This step requires Python 3 to be installed.
Install the MLflow Python package:
pip install mlflow-skinny
Then, run the following Python script to log a parameter and metric to FastTrackML:
import mlflow
import random
# Set the tracking URI to the FastTrackML server
mlflow.set_tracking_uri("http://localhost:5000")
# Set the experiment name
mlflow.set_experiment("my-first-experiment")
# Start a run
with mlflow.start_run():
# Log a parameter
mlflow.log_param("param1", random.randint(0, 100))
# Log a metric
mlflow.log_metric("foo", random.random())
# metrics can be updated throughout the run
mlflow.log_metric("foo", random.random() + 1)
mlflow.log_metric("foo", random.random() + 2)
After running this script, you should see the following output from http://localhost:5000/aim/:
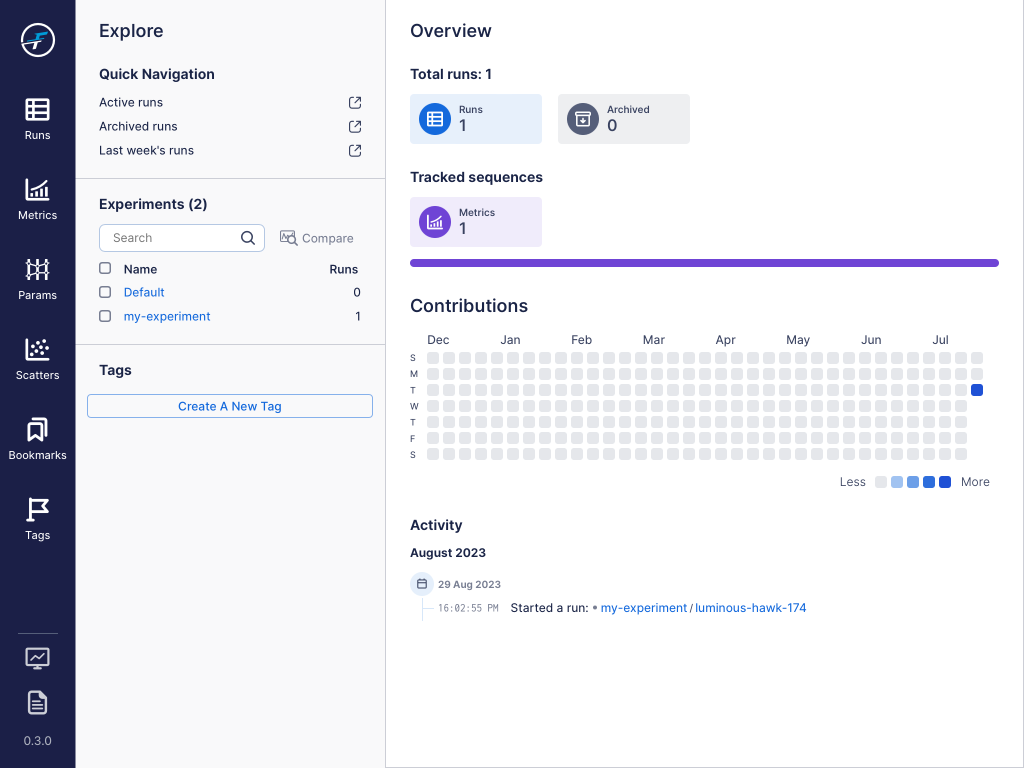
From here you can check out the metrics and run information to see more details about the run.
Contact Us
We would love to hear from you! FastTrackML is a brand new project and any contribution would make a difference!
Or, join the #fasttrackml channel on the MLOps.community Slack!